AIがつくる映像の未来 ― デジタルパーソン技術の最新動向
近年、画像生成 AI(例:Stable Diffusion、DALL·E 系列、Midjourney など)のブレークスルーを起点として、動画生成・アバター生成へと技術が急速に進展しています。中でも、「静止画 × 音声 / モーション入力 → 動画」変換を軸とする技術群は、バーチャルアバター、デジタル人材、仮想タレントといった応用を強く刺激しており、メディア、マーケティング、配信、ゲーム、教育など多領域で注目されています。
本記事では、急速に進展している技術(OSS や研究レベル含む)を中心に、バーチャル・デジタルパーソン生成の最新潮流を整理します。特に、以下二つの OSS/研究プロジェクトを中核として取り上げつつ、それらと関連する技術体系を紐解きます。
・MoDA(Mapping-Once Audio-driven Portrait Animation)
・LivePortrait(Efficient Portrait Animation with Stitching / Retargeting)
技術分類とアーキテクチャ観点
まず、バーチャル・デジタルパーソン生成を技術分類的に整理すると、主に以下ような分類軸が考えられます。
| 分類軸 | 具体内容 | 主な課題 / 拡張方向 |
|---|---|---|
| 入力モダリティ | 音声 → 顔・唇・表情モーション、静止画+リファレンス動画 → アニメーション、テキスト → 映像変換 | 入力モダリティの多様性対応(音声+表情+視点変化) |
| モーション駆動設計 | リップ同期(音素 → 口型)/顔部モーション/頭部回転/まばたき/視線変化 | 各成分の協調性、滑らかさ、過学習・歪み制御 |
| 解像度・画質 | 高解像度化、超解像補正、顔細部保持 | ノイズ制御、アップサンプリング品質維持 |
| 実行効率 | 推論速度/リアルタイム性 | サンプリングステップ数、軽量モデル設計、量子化・蒸留 |
| 制御可能性 | モーション編集性、モーション転移、ポーズ制御、ループ制御 | ユーザーインタラクション性、微調整可能性 |
| 安全性・倫理性 | フェイク検知、著作権対応、深偽造抑制 | 水印、トレーサビリティ、バイアス対応 |
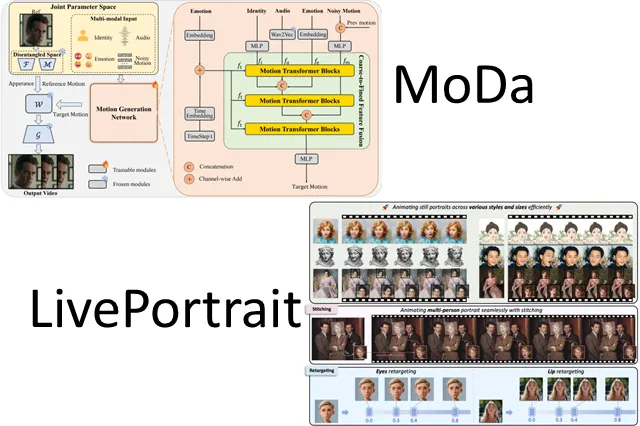
MoDA(音声駆動ポートレートアニメーション)
概要
MoDA(Mapping-Once Audio-driven Portrait Animation with Dual Attentions)は、音声入力をもとにポートレート(顔)動画を生成するための手法で、口唇運動、頭部動作、目の動きなどを協調させて自然なアニメーションを生成することを目指しています。
この手法のコア思想は「Dual Attention(複数注意機構)」を導入して、リップ同期と他の顔モーションを分離かつ統合的に扱う点にあります。具体には以下三段構成をとっています。
1. Mapping-Once ネットワーク
音声から、中間の「話者表現 / モーション表現」を一括でマッピング
2. Facial Composer ネットワーク
詳細な顔ランドマーク生成
3. Temporal-Guided Renderer
時間方向の整合性を担保しつつ、最終映像レンダリング
このアプローチにより、リップ動作と頭部・まばたき等の動作が別々に最適化されやすく、これらの協調を改善できるという強みがあります。実験結果でも、既存手法と比較して自然性・表情豊かさで優位性を示しています。
強み・制約・応用展望
強み
・音声 → 顔アニメーション変換に特化しており、音声駆動型アバター用途に直接的に適用可能
・比較的シンプルな構成であるため、制御性や拡張性を持たせやすい
・複数話者対応可能性や多様な顔形状への拡張の余地
制約・課題
・背景や体全体、歩行アニメーションなど顔以外の動作生成には未対応
・高解像度化や顔のディテール表現には限界がある可能性
・時系列モーションの長時間安定性や揺らぎ抑制のチューニングが必要
応用方向
・音声ナレーションに合わせて話すバーチャル人材(例:AI アナウンサー、AI 担当者キャラクタ)
・オンライン教育、音声インタラクション型サポートアバター
・ライブ配信補助、キャラクタ代行(声・顔同期型)
LivePortrait(効率的ポートレートアニメーション+リターゲティング)
概要
LivePortrait(KwaiVGI / GitHub リポジトリ) は、静止画ポートレートを基に、リファレンス動画像(ドライバー映像)からモーションを転写し、自然な顔動作を生成する OSS 実装です。
具体的には、「Stitching」と「Retargeting Control」をキー概念とし、複数モーションソースを統合・補間するアプローチを特徴とします。リファレンス動画のモーションを別の顔へと適用(リターゲティング)する柔軟性を持ちつつ、モーション間の繋ぎ目(Stitching)を滑らかに保つ工夫がなされています。
GitHub リポジトリでは、PyTorch 実装が公開されており、今後改善や拡張が期待されている段階です。
強み・制約・応用展望
強み
・静止画 → モーション適用型という典型的なユースケースに対して動作可能
・モーションの組み合わせや補間制御を比較的自由に設計できる構造
・OSS 実装であるため、カスタム改変や他モジュールとの統合が可能
制約・課題
・音声駆動同期(リップ同期)に関しては、外部手法との組み合わせが必要
・高解像度化、顔ディテール保持は既存限界あり
・時間整合性・揺らぎ制御はさらなる改良を要する可能性
応用方向
・リファレンス動画 → 任意顔ポートレートへのモーション転写
・キャラクタアニメーション生成、VFX 補助ツール
・ユーザーが撮った静止画を元に、表情つき動画を作るコンテンツ UX
他に注目すべき関連/後続技術
MoDA や LivePortrait を単独で使うだけでなく、次のような研究/技術トレンドも押さえておくと、将来的な拡張や実用化を見越した設計が可能です。
Veo(Google / DeepMind)
2024 年 5 月、Google(DeepMind が主体とされる)が Veo というテキスト → 動画生成モデルを発表しました。
・Veo はプロンプト(自然言語)をもとに動画を生成でき、1080p クラスの長尺動画を目指すという報道があります。
・さらに、後続バージョン Veo 2、さらには Veo 3 において、映像と同期した音声生成(BGM/効果音含む)も可能とされる方向性が報じられています。
・ただし、Veo は汎用動画生成モデルであり、バーチャル・デジタルパーソン生成(顔アバター)に特化した制御やモーション制御性は現時点では限定的です。
このような汎用動画生成技術と MoDA / LivePortrait のような顔モーション制御技術を統合するアーキテクチャ設計は、将来の強力な方向性になり得ます。
Sora(OpenAI)
OpenAI は 2024 年 2 月、「Sora」というテキスト → 映像生成モデルを発表しました。
・Sora は最大 1 分程度の動画生成を可能とし、比較的高精度な被写界深度、シーン展開、物体運動などを組み込んだ映像を生成することを目指しています。
・ただし、顔アバター制御やリップ同期、ユーザー指定モーション制御といった強い制御性要件には、Sora 単独では十分とは言えません。
Sora のような汎用生成段階と、顔特化モジュール (MoDA, LivePortrait 等) を組み合わせるハイブリッド構成の研究・実装も期待されます。
技術系統図(概念モデル)
以下は、本稿で紹介した技術群を「汎用動画生成 ↔ 顔アバター生成モジュール ↔ 高速化技術」の観点で整理した概念モデル案です。
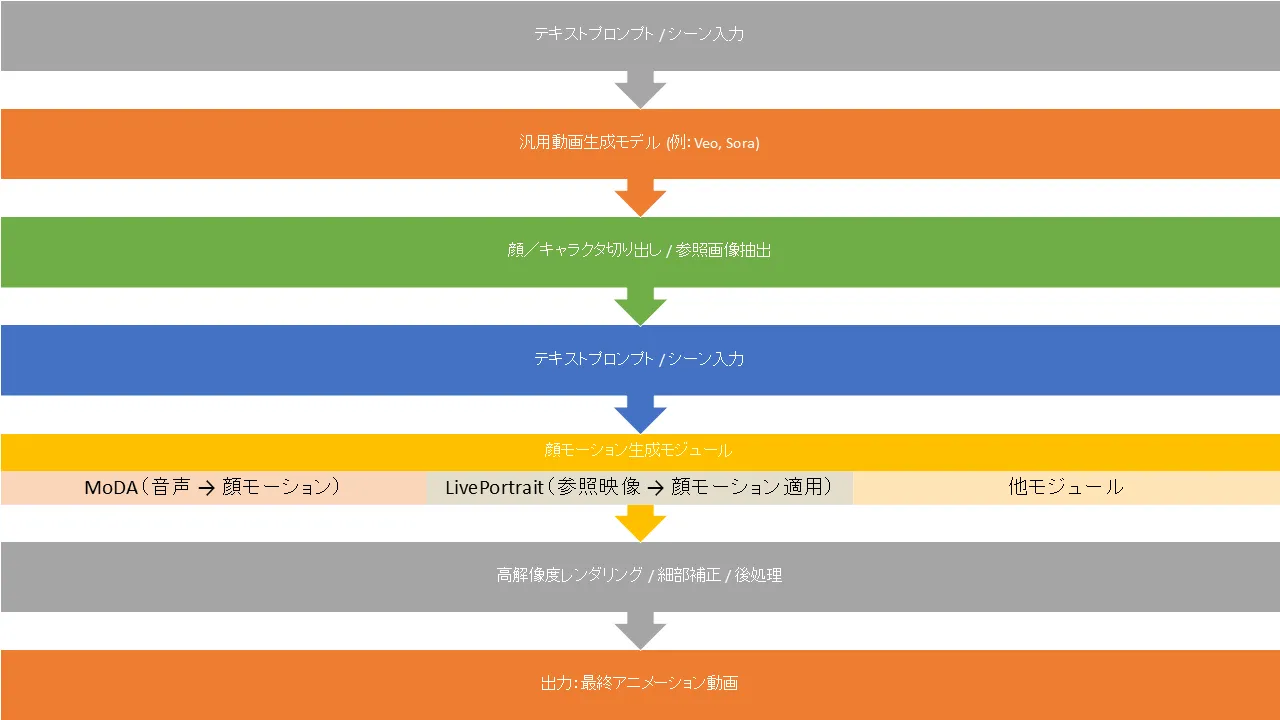
このような系統構成を念頭におきつつ、各モジュールで改善や最適化を行うアーキテクチャ設計が、バーチャル・デジタルパーソン生成基盤を構築する際の基本戦略となります。
実用化/事業応用上の考察と課題
応用シナリオ例
・バーチャル人物を使ったマーケティング動画、PR コンテンツ
・音声案内を伴う仮想アナウンサー、ナレーター
・Vチューバーやバーチャルホスト、ライブ配信支援
・教育/eラーニング領域で、対話型アバター教材
・カスタマサポート用 AI アバター(音声対話 + 顔表現)
課題およびリスク要因
1. フェイク/ディープフェイクリスク
生成された動画が実在人物と混同される可能性 ⇒ 実装時には水印、フェイク検知、トレーサビリティ対応が不可欠
2. 著作権・肖像権対応
顔データ、音声データ、モーションデータには権利関係が絡みやすいため、ライセンス管理やデータ取得ポリシー設計が鍵
3. モーション・顔表現の不自然性
長尺動画での揺らぎ、モーション断絶、顔歪み、ライティング違和感など、品質制御には高度な安定化設計が必要
4. 計算コスト・リアルタイム性
モデルのサイズ、サンプリングステップ数、推論速度、GPU コストなどの制約
5. 多様性・公平性
話者属性、肌色、年齢、表情多様性など、学習データバイアスを含めた設計
6. UX・操作性設計
ユーザー(コンテンツ制作者)が使いやすい制御インタフェース(モーション調整、表情編集、同期制御など)を設計
実践導入のステップ(提案)
1. プロトタイプ構築
MoDA や LivePortrait をベースに、簡易入力(音声+参照顔) → 出力動画生成パイプラインを構築
2. 品質評価とチューニング
フレーム整合性、揺らぎ抑制、表情自然性などを定量/定性評価
3. 高速化・最適化
蒸留、量子化、1 ステップ生成モデルとのハイブリッド統合
4. 制御系拡張
モーション編集 UI、モーション転移、ループ生成、対話同期連携
5. 倫理・安全対応
フェイク検出、透かし表記、使用ポリシー、利用制限設計
おわりに
MoDA や LivePortrait は、顔モーション生成という特化モジュールとして非常に興味深く、特に制御性や編集性を重視した応用系には不可欠な技術基盤になり得ます。一方で、画質・リアルタイム性・安全性・制御インタラクション性といった課題を克服するためには、上記に挙げた汎用生成モデルや高速化技術とのハイブリッド構成・統合設計が鍵となるでしょう。